IVS、サロゲートペアが混じった文字列をJavaのWebアプリでワードカウントする
(結論:java.text.BreakIteratorは「サロゲートペア文字 + IVS」の8バイト文字も1文字としてカウントしてくれる)
先日、IPAmj明朝フォントを使ってIVSを含んだUnicode文字を一覧表示してみました。

一覧表示したフォントが持つ文字コードサイズには以下の種類があるはずです。
- Unicode文字(2Byte)= 2Byte文字
- サロゲート文字(4Byte)= 4Byte文字
- Unicode文字(2Byte) + IVS(4Byte)= 6Byte文字
- サロゲート文字(4Byte) + IVS(4Byte) = 8Byte文字
これらバラバラのサイズの文字コードを持つ文字の、見た目上の文字数を正確に数えられるかJavaで試しました。
調査対象の文字列
6万文字をカウントするのは効率が悪いので、MJ文字情報一覧表の.xls から前述の4パターンを全て含む10文字が並ぶ区画、MJ060378~MJ067953を選んで文字数をカウントしてみます。
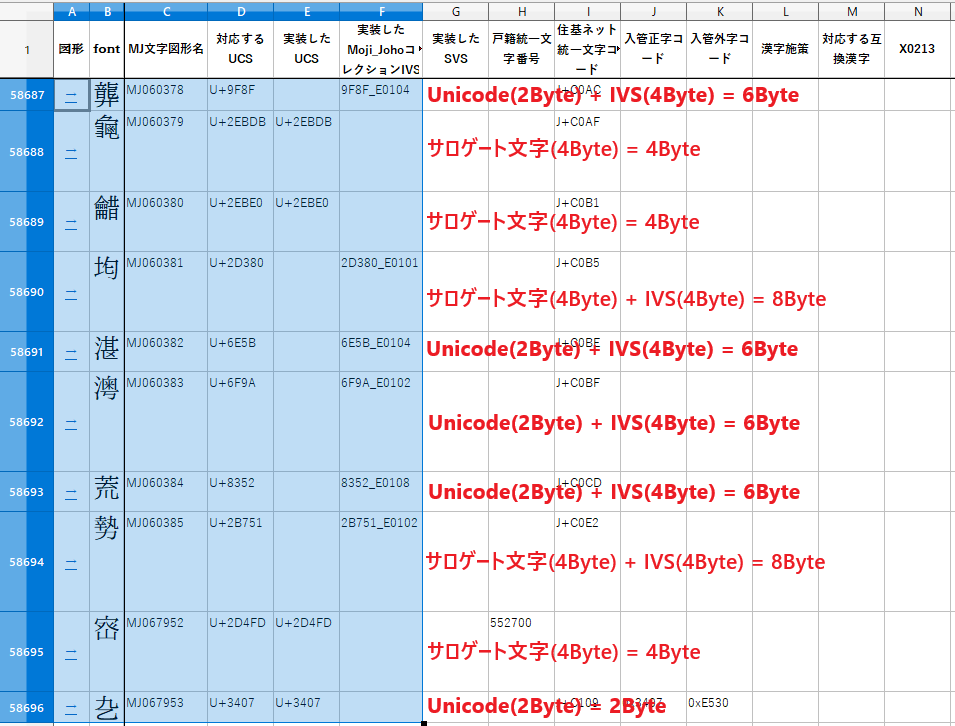
Webで表示する用にエスケープしてみるとこんな感じの10文字コードです。0x10000以上はサロゲートペアにエンコードして4バイトになるのでカッコ内のバイト数になります。
&#x9F8F&#xE0104 (6Byte)
&#x2EBDB (4Byte)
&#x2EBE0 (4Byte)
&#x2D380&#xE0101 (8Byte)
&#x6E5B&#xE0104 (6Byte)
&#x6F9A&#xE0102 (6Byte)
&#x8352&#xE0108 (6Byte)
&#x2B751&#xE0102 (8Byte)
&#x2D4FD (4Byte)
&#x3407 (2Byte)10文字で計54バイトですね。String.length()は2バイトバウンダリで数えるので27文字と回答することが今から予想されます。
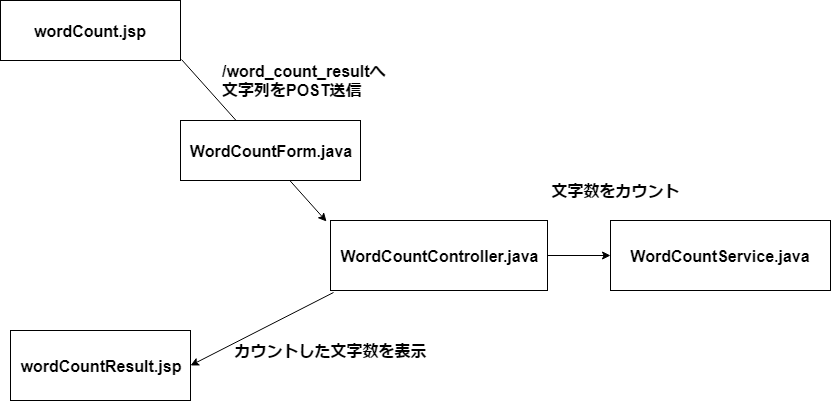
JavaのWebアプリで数えてみる
プロジェクトは前回まで使っていたSpringBootです。
こんな流れで。
wordCount.jsp
/word_countにアクセスすると表示され、前述の10文字をコントローラから貰い、input type=”text”に表示します。
文字化けせずに表示出来るようにfont-familyにはIPAmj明朝を指定しておきます。(CSS分けた方がいいですが、分かり易いので取りあえずstyleに直書きしてます)
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%>
<%@ taglib prefix="form" uri="http://www.springframework.org/tags/form"%>
<!DOCTYPE html>
<html>
<head>
<%@ include file="/WEB-INF/jsp/head.jsp"%>
</head>
<body>
<header class="sticky-top">
<h3>文字数チェック</h3>
</header>
<main class="container">
<form:form action="/word_count_result" method="POST" modelAttribute="wordCountForm">
<div class="form-group">
<form:input path="inputValue" class="form-control"
style="font-family: IPAmj明朝; height: 96px;" value="${codePoints}" htmlEscape="false" />
<input type="submit" value="文字列をワードカウント" class="btn btn-primary" />
</div>
</form:form>
</main>
</body>
</html>WordCountForm.java
/word_count_resultに渡すフォーム。inputValueには10文字分の文字コードが入ります。(バイト数は54Byteだけど)
package com.example.demo;
public class WordCountForm {
private String inputValue;
public String getInputValue() {
return inputValue;
}
public void setInputValue(String inputValue) {
this.inputValue = inputValue;
}
}wordCountResult.jsp
数えた文字数をコントローラから貰って表示するだけです。
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%>
<%@ taglib prefix="form" uri="http://www.springframework.org/tags/form"%>
<!DOCTYPE html>
<html>
<head>
<%@ include file="/WEB-INF/jsp/head.jsp"%>
</head>
<body>
<header class="sticky-top">
<h3>文字数チェック結果</h3>
</header>
<main class="container">
<p style="font-size: 32px;">
String.length()で図った文字数 : ${length1}
</p>
<p style="font-size: 32px;">
BreakIteratorで計った文字数 : ${length2}
</p>
</main>
</body>
</html>WordCountService.java
ワードカウントを行う処理をServiceに切り分けておきます。BreakIteratorで文字列をパースするとcurrent()で現在パース中のバイト配列インデックスが返却されます。
バイト配列中のどこからどこまでが一文字か分かったら、String文字列からその部分をコードポイント配列として抜き出しています。
package com.example.demo;
import java.text.BreakIterator;
import java.util.ArrayList;
import java.util.List;
import org.springframework.stereotype.Service;
@Service
public class WordCountService {
// 引数inputを一文字ずつコードポイント配列にして返却
public char[][] toUnicodeArray(String input) {
List<char[]> utf16List = new ArrayList<char[]>();
BreakIterator bi = BreakIterator.getCharacterInstance();
bi.setText(input);
int start = 0;
int cnt = 0;
while (bi.next() != BreakIterator.DONE) {
// サロゲートペアを考慮した現在パース中の
// バイト配列インデックスを返してくれる
int current = bi.current();
// BreakIteratorが1文字として検知した分のサイズを
// String文字列からコードポイント配列化
char[] codePointArray = toCodePointArray(input, start, current);
utf16List.add(codePointArray);
start = current;
}
char[][] ret = utf16List.toArray(new char[utf16List.size()][]);
return ret;
}
// BreakIteratorが1文字と判定した範囲をコードポイント配列化
public char[] toCodePointArray(String input, int start, int end) {
int len = end - start;
char[] ret = new char[len];
for (int i = 0; start < end; start++, i++) {
ret[i] = input.charAt(start);
}
return ret;
}
}WordCountController.java
/word_countにアクセスされるとwordCountResult.jspを返却、/word_count_resultにアクセスされると文字数を数えて結果をwordCountResult.jspで表示します。
package com.example.demo;
import java.util.ArrayList;
import java.util.List;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.ModelAttribute;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
@Controller
public class WordCountController {
private WordCountService wordCountService;
@ModelAttribute
public WordCountForm setUpForm() {
return new WordCountForm();
}
public WordCountController(WordCountService wordCountService) {
this.wordCountService = wordCountService;
}
@RequestMapping(path = "/word_count", method = { RequestMethod.GET })
public String wordCount(Model model) {
List<String> codeList = new ArrayList<String>();
codeList.add("&#x9F8F&#xE0104");
codeList.add("&#x2EBDB");
codeList.add("&#x2EBE0");
codeList.add("&#x2D380&#xE0101");
codeList.add("&#x6E5B&#xE0104");
codeList.add("&#x6F9A&#xE0102");
codeList.add("&#x8352&#xE0108");
codeList.add("&#x2B751&#xE0102");
codeList.add("&#x2D4FD");
codeList.add("&#x3407");
String codePoints = String.join("", codeList);
model.addAttribute("codePoints", codePoints);
return "wordCount";
}
@RequestMapping(path = "/word_count_result", method = { RequestMethod.POST })
public String wordCountResult(WordCountForm form, Model model) {
char[][] codePoints =
this.wordCountService.toUnicodeArray(form.getInputValue());
model.addAttribute("length1", form.getInputValue().length());
model.addAttribute("length2", codePoints.length);
return "wordCountResult";
}
}実装完了です。
動作確認
SpringBootを実行してブラウザでhttp://localhost:8080/word_countにアクセス。「font-family: IPAmj明朝;」が効いて文字化けせずに期待通りの文字が表示されています。
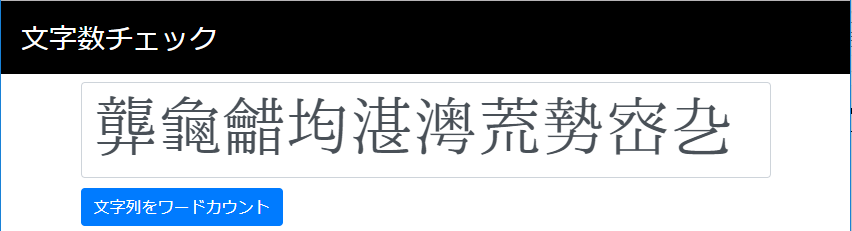
文字数チェックの為にボタンを押してみると・・・期待通りの回答が返ってきました。

String.length()はやはり54Byte / 2Byte = 27文字として返却し、IVSを含めたサロゲートをBreakIteratorで考慮した場合は正解の10文字でした。
Unicodeの文字数カウントはBreakIteratorに任せて安心
2、4、6、8Byteの文字が混在していてもjava.text.BreakIteraterさんはコードポイントを判断して正しい文字数を返してくれる素敵なAPIでした。