無料で自由に使える日本全国の企業データベースをPostgreSQLで作る
開発するシステムよっては一覧から企業を選択する機能があるかも知れません。「企業データベース」でググると沢山の商用企業データベースが出てきます。
「でも・・・お高いんでしょう?」
いいえ、なんと今なら・・・なんてことは有りません。はい、下手をすると家が買えるほどにお高いです。一つオマケで付いてくることもありません。
これらのデータ製品は業種によっては有用ですが、我々一介のシステム屋さんが欲するニーズには情報が高密度過ぎて料金が釣り合いません。
純粋に「日本に存在する法人企業の一覧が欲しい」程度のニーズであれば、国税庁から公開されているオープンデータを使用することで最低限かつ自分だけの企業一覧データベースを無料で構築することが出来ます。
「開発アプリ内で地域の企業一覧を表示してユーザに選択させたい」のようなニーズに応える為、このオープンデータをPostgreSQLに入れてシステムから利用できるようにしてみます。
構築前の準備
使用環境
作業環境はこんな感じですがOSは不問です。
- DBサーバ:CentOS 7.6、PostgreSQL 11
- DBクライアント:Windows 10、A5:SQL Mk-2
企業一覧CSVファイルを入手する
国税庁が運営する「法人番号公表サイト」で、納税している日本全国の法人の「基本3情報」をCSVまたはXMLで入手することが出来ます。

法人の基本3情報とは以下を指します。
- 商号または名称(会社名)
- 本店又は主たる事務所の所在地(住所)
- 法人番号(企業のユニーク番号)
この他にもダウンロードファイルには登記の更新年月日や登記の事由他、30カラム分のデータが保存されています。どんなデータが載っているかは後でDBスキーマを作るので確認してください。
上記サイトから全国47都道府県分のCSV(Unicode)ZIPファイルをダウンロードしておきます。
CSVをインポートするデータベースを準備
CentOS7にPostgreSQL11を入れた後、以下記事で外部PCから接続出来るようにして一般作業ユーザ「devel」を作成した状態です。(ユーザ名は任意で)

SSHでCentOSにログイン、postgresスーパーユーザでdevelユーザ用DB「enterprises」を作成しておきます。
// postgresユーザに移行
# su - postgres
// psql起動
-bash-4.2$ /usr/pgsql-11/bin/psql
psql (11.4)
"help" でヘルプを表示します。
// develユーザ用のデータベース「enterprises」を作成
postgres=# CREATE DATABASE enterprises OWNER devel;
CREATE DATABASE
// 作成出来たか確認
postgres=# \l
データベース一覧
名前 | 所有者 | エンコーディング | 照合順序 | Ctype(変換演算子) | アクセス権限
-------------+----------+------------------+-------------+-------------------+-----------------------
enterprises | devel | UTF8 | ja_JP.UTF-8 | ja_JP.UTF-8 |データベースへの接続を確認
Windowsから神DBクライアント「A5:SQL Mk-2」を使って、上記データベースへの接続を確認しておきます。

A5の使用方法は上記公式サイトの「オンラインヘルプ」を見れば一通り分かるので参照してください。
今回はこんな感じでA5からPostgreSQLに接続しました。
構築開始
DBスキーマ、テーブルを作成
法人番号公表サイトに基本3情報ファイルのデータ定義書がPDFとExcelで公開されています。(下記はPDFへのリンク)
https://www.houjin-bangou.nta.go.jp/documents/k-resource-dl-ver4.pdf
コード値を持っているカラムはマスタテーブルを作って外部キーにしておきましょう。PDFを参照しながらA5でER図を新規作成してみます。
(ER図の作成手順もA5公式で詳しく参照されています)
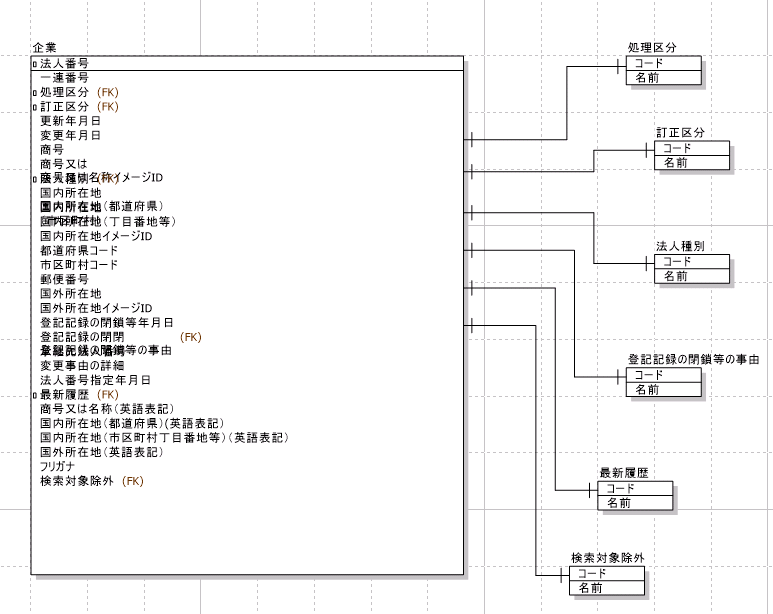
作成した上記ER図からテーブルの雛型となるDDLを自動生成します。
-- Project Name : enterprises
-- Date/Time : 2019/09/08 21:46:20
-- Author : naka
-- RDBMS Type : PostgreSQL
-- Application : A5:SQL Mk-2
/*
BackupToTempTable, RestoreFromTempTable疑似命令が付加されています。
これにより、drop table, create table 後もデータが残ります。
この機能は一時的に $$TableName のような一時テーブルを作成します。
*/
-- 検索対象除外
--* RestoreFromTempTable
create table hihyoji (
code char(1)
, name varchar(30)
, constraint hihyoji_PKC primary key (code)
) ;
-- 最新履歴
--* RestoreFromTempTable
create table latest (
code char(1)
, name varchar(30)
, constraint latest_PKC primary key (code)
) ;
-- 登記記録の閉鎖等の事由
--* RestoreFromTempTable
create table closeCause (
code char(2)
, name varchar(30)
, constraint closeCause_PKC primary key (code)
) ;
-- 法人種別
--* RestoreFromTempTable
create table kind (
code char(3)
, name varchar(30)
, constraint kind_PKC primary key (code)
) ;
-- 訂正区分
--* RestoreFromTempTable
create table correct (
code char(1)
, name varchar(30)
, constraint correct_PKC primary key (code)
) ;
-- 処理区分
--* RestoreFromTempTable
create table process (
code char(2)
, name varchar(30)
, constraint process_PKC primary key (code)
) ;
-- 企業
--* RestoreFromTempTable
create table enterprises (
sequenceNumber integer
, corporateNumber char(13) not null
, process char(2) not null
, correct char(1) not null
, updateDate date
, changeDate date
, name varchar(150)
, nameImageId char(8)
, kind char(3) not null
, prefectureName varchar(10)
, cityName varchar(20)
, streetNumber varchar(300)
, addressImageId char(8)
, prefectureCode char(2)
, cityCode char(3)
, postCode char(7)
, addressOutside varchar(300)
, addressOutsideImageId char(8)
, closeDate date
, closeCause char(2)
, successorCorporateNumber char(13)
, changeCause varchar(500)
, assignmentDate date
, latest char(1) not null
, enName varchar(300)
, enPrefectureName varchar(9)
, enCityName varchar(600)
, enAddressOutside varchar(600)
, furigana varchar(500)
, hihyoji char(1)
, constraint enterprises_PKC primary key (corporateNumber)
) ;
alter table enterprises
add constraint enterprises_FK1 foreign key (hihyoji) references hihyoji(code);
alter table enterprises
add constraint enterprises_FK2 foreign key (latest) references latest(code);
alter table enterprises
add constraint enterprises_FK3 foreign key (closeCause) references closeCause(code);
alter table enterprises
add constraint enterprises_FK4 foreign key (kind) references kind(code);
alter table enterprises
add constraint enterprises_FK5 foreign key (correct) references correct(code);
alter table enterprises
add constraint enterprises_FK6 foreign key (process) references process(code);
comment on table hihyoji is '検索対象除外';
comment on column hihyoji.code is 'コード';
comment on column hihyoji.name is '名前';
comment on table latest is '最新履歴';
comment on column latest.code is 'コード';
comment on column latest.name is '名前';
comment on table closeCause is '登記記録の閉鎖等の事由';
comment on column closeCause.code is 'コード';
comment on column closeCause.name is '名前';
comment on table kind is '法人種別';
comment on column kind.code is 'コード';
comment on column kind.name is '名前';
comment on table correct is '訂正区分';
comment on column correct.code is 'コード';
comment on column correct.name is '名前';
comment on table process is '処理区分';
comment on column process.code is 'コード';
comment on column process.name is '名前';
comment on table enterprises is '企業';
comment on column enterprises.sequenceNumber is '一連番号';
comment on column enterprises.corporateNumber is '法人番号';
comment on column enterprises.process is '処理区分';
comment on column enterprises.correct is '訂正区分';
comment on column enterprises.updateDate is '更新年月日';
comment on column enterprises.changeDate is '変更年月日';
comment on column enterprises.name is '商号';
comment on column enterprises.nameImageId is '商号又は商号又は名称イメージID';
comment on column enterprises.kind is '法人種別';
comment on column enterprises.prefectureName is '国内所在地国内所在地(都道府県)';
comment on column enterprises.cityName is '国内所在地(市区町村)';
comment on column enterprises.streetNumber is '国内所在地(丁目番地等)';
comment on column enterprises.addressImageId is '国内所在地イメージID';
comment on column enterprises.prefectureCode is '都道府県コード';
comment on column enterprises.cityCode is '市区町村コード';
comment on column enterprises.postCode is '郵便番号';
comment on column enterprises.addressOutside is '国外所在地';
comment on column enterprises.addressOutsideImageId is '国外所在地イメージID';
comment on column enterprises.closeDate is '登記記録の閉鎖等年月日';
comment on column enterprises.closeCause is '登記記録の閉鎖等の事由';
comment on column enterprises.successorCorporateNumber is '承継先法人番号';
comment on column enterprises.changeCause is '変更事由の詳細';
comment on column enterprises.assignmentDate is '法人番号指定年月日';
comment on column enterprises.latest is '最新履歴';
comment on column enterprises.enName is '商号又は名称(英語表記)';
comment on column enterprises.enPrefectureName is '国内所在地(都道府県)(英語表記)';
comment on column enterprises.enCityName is '国内所在地(市区町村丁目番地等)(英語表記)';
comment on column enterprises.enAddressOutside is '国外所在地(英語表記)';
comment on column enterprises.furigana is 'フリガナ';
comment on column enterprises.hihyoji is '検索対象除外';論理名を入れたのでちょっと長くなりましたね。
あと「登記記録の閉鎖等の事由」だけはCSVに値を持っていないことがあるので、外部キーですがNOT NULLは外しています。
このDDLをA5から流せばテーブル構築は完了です。7テーブル出来ましたね。
enterprises=> \d
リレーション一覧
スキーマ | 名前 | 型 | 所有者
----------+-------------+----------+--------
public | closecause | テーブル | devel
public | correct | テーブル | devel
public | enterprises | テーブル | devel
public | hihyoji | テーブル | devel
public | kind | テーブル | devel
public | latest | テーブル | devel
public | process | テーブル | devel
(7 行)マスタテーブルデータを投入
データ定義PDFを見ながら、本テーブル「enterprises」が保持するコード値に対応するデータをマスタテーブルに入れていきます。
テーブル結合すれば0とか1ではなく「新規」や「変更」のような論理名で表示が出来るようになります。
-- 処理区分マスタ
INSERT INTO process VALUES('01', '新規');
INSERT INTO process VALUES('11', '商号または名称の変更');
INSERT INTO process VALUES('12', '国内所在地の変更');
INSERT INTO process VALUES('13', '国外所在地の変更');
INSERT INTO process VALUES('21', '登記記録の閉鎖等');
INSERT INTO process VALUES('22', '登記記録の復活等');
INSERT INTO process VALUES('71', '吸収合併');
INSERT INTO process VALUES('72', '吸収合併無効');
INSERT INTO process VALUES('81', '商号の登記の抹消');
INSERT INTO process VALUES('99', '削除');
-- 訂正区分マスタ
INSERT INTO correct VALUES('0', '訂正以外');
INSERT INTO correct VALUES('1', '訂正');
-- 法人種別マスタ
INSERT INTO kind VALUES('101', '国の機関');
INSERT INTO kind VALUES('201', '地方公共団体');
INSERT INTO kind VALUES('301', '株式会社');
INSERT INTO kind VALUES('302', '有限会社');
INSERT INTO kind VALUES('303', '合名会社');
INSERT INTO kind VALUES('304', '合資会社');
INSERT INTO kind VALUES('305', '合同会社');
INSERT INTO kind VALUES('399', 'その他の設立登記法人');
INSERT INTO kind VALUES('401', '外国会社等');
INSERT INTO kind VALUES('499', 'その他');
-- 登記記録の閉鎖等の事由マスタ
INSERT INTO closecause VALUES('01', '清算の終了');
INSERT INTO closecause VALUES('11', '合併による解放等');
INSERT INTO closecause VALUES('21', '登記官による閉鎖');
INSERT INTO closecause VALUES('31', 'その他の清算の結了等');
-- 検索対象除外マスタ
INSERT INTO latest VALUES('0', '過去情報');
INSERT INTO latest VALUES('1', '最新情報');
-- 検索対象除外マスタ
INSERT INTO hihyoji VALUES('0', '検索対象');
INSERT INTO hihyoji VALUES('1', '検索対象除外');これもA5から流しておきます。
DB構造とマスタデータ登録が終わりました。後はCSVデータをPostgreSQLに入れて行くだけです。
ダウンロードしたCSVファイルを一括インポートする
A5のメニューから「テーブル」→「CSVインポート」を選べば、前項までに作成したenterprisesテーブルに、ダウンロードしたCSVデータを投入することが出来ます。
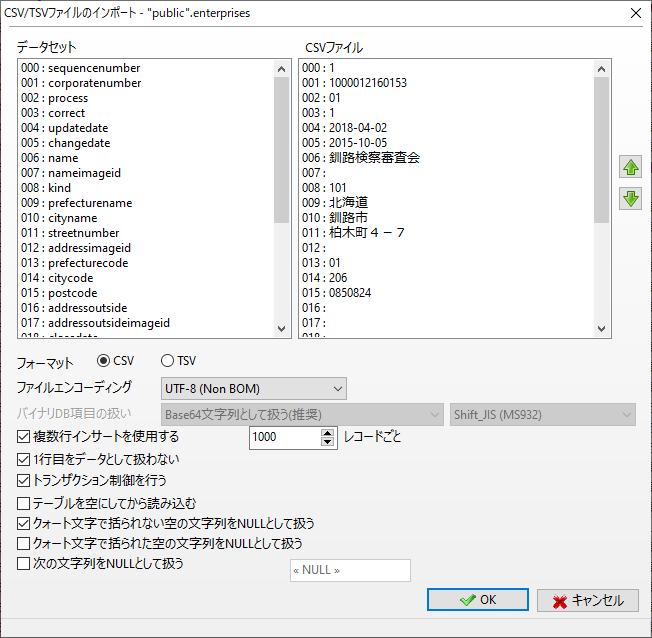
ただ、これを47都道府県分繰り返すのは少々かったるいですね。また後日再構築する可能性もあるので、一括で入れられるようにしておきます。
落としてきた47個のzipファイルをscpコマンドなりWinSCPなりでCentOS側に転送。

/var/lib/pgsql/tmp/にzipファイルたちを置いておきます。配備したらunzipedディレクトリに纏めて解凍します。
# unzip '*.zip' -d unziped
Archive: 16_toyama_all_20190830.zip
inflating: unziped/16_toyama_all_20190830.csv
inflating: unziped/16_toyama_all_20190830.csv.asc
(snip)
# chown -R postgres.postgres ./unziped
# cd unziped
# pwd
/var/lib/pgsql/tmp/unziped
# ls -lt
合計 941464
-rw-r--r--. 1 postgres postgres 5493321 8月 30 16:27 05_akita_all_20190830.csv
-rw-r--r--. 1 postgres postgres 490 8月 30 16:27 05_akita_all_20190830.csv.asc
-rw-r--r--. 1 postgres postgres 6003653 8月 30 16:27 19_yamanashi_all_20190830.csv
-rw-r--r--. 1 postgres postgres 490 8月 30 16:27 19_yamanashi_all_20190830.csv.asc
-rw-r--r--. 1 postgres postgres 490 8月 30 16:27 20_nagano_all_20190830.csv.asc
-rw-r--r--. 1 postgres postgres 12407055 8月 30 16:27 21_gifu_all_20190830.csv
(snip)47都道府県分の企業一覧CSVファイルが/var/lib/pgsql/tmp/unzipedに出来ました。
copyコマンドSQLファイルを作成
CSVをPostgreSQLにインポートするにはcopyコマンドを使います。

47都道府県分流すのはこれまたかったるいので、SQLファイルにしておきます。ここからはpostgresユーザで作業。
# su - postgres
-bash-4.2$ cd /var/lib/pgsql/tmp/unziped
// copy文を47都道府県分作ってcopy.sqlファイルに吐くワンライナー
-bash-4.2$ ls -1 | grep -e ".csv$" | xargs readlink -f | xargs -I{} echo copy enterprises from \'{}\' with csv\; > copy.sql
// 出来たcopy.sqlの中身
-bash-4.2$ cat copy.sql
copy enterprises from '/var/lib/pgsql/tmp/unziped/01_hokkaido_all_20190830.csv' with csv;
copy enterprises from '/var/lib/pgsql/tmp/unziped/02_aomori_all_20190830.csv' with csv;
copy enterprises from '/var/lib/pgsql/tmp/unziped/03_iwate_all_20190830.csv' with csv;
(snip)ダウンロードしてきた47都道府県分のCSVを一括でインポートするSQLファイルが出来ました。あと一息です。
インポート
postgresユーザでunzipedディレクトリに居る状態で、enterprisesデータベースに入ります。
-bash-4.2$ /usr/pgsql/bin/psql -d enterprisesSQLファイルを実行する\iで、copy.sqlを実行。enterprisesテーブルにデータを投入。
enterprises=# \i copy.sql
COPY 201674
COPY 34584
COPY 30522
COPY 71546
(snip)
COPY 32192
COPY 38753
COPY 27605
COPY 48966470万件を超えるデータを一気に取りこめました。日本の法人は270万社くらいなのにこの件数なのは、閉鎖や合併の履歴が入っている為です。法人以外のフリーランスや個人事業主が入っている訳ではありません。
enterprises=# select count(*) from enterprises;
count
---------
4778310
(1 行)構築したデータベースを使ってみる
A5に戻って試しにSQLを流してみましょう。
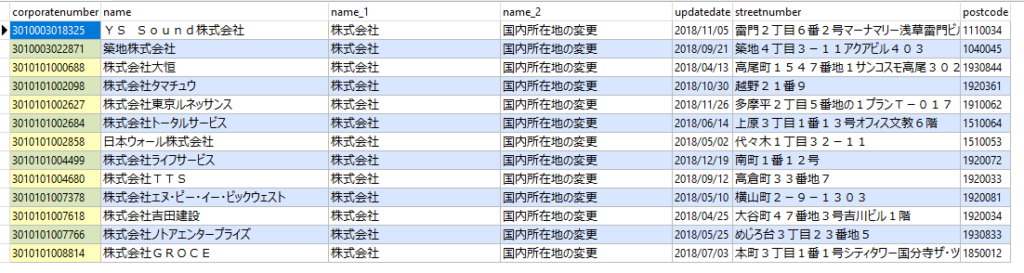
東京で2018年に所在地を移転した株式企業を洗ってみます。
SELECT
e.corporatenumber,
e.name,
k.name,
p.name,
e.updatedate,
e.streetnumber,
e.postcode
FROM
enterprises AS e,
kind AS k,
process AS p
WHERE
e.prefecturename = '東京都' AND
e.kind = k.code AND
k.code = '301' AND
e.process = p.code AND
e.process = '12' AND
updatedate BETWEEN '2018-01-01' AND '2018-12-31';37,537社ありました。
細かい検索条件を求められず、地域ごとの企業一覧を出す、既に閉鎖しているのか、いつ登記されたのか、のような条件ならこれでも十分使えそうですね。
まとめ
このデータベースでは資本金も、取締役の名前、従業員数も分かりませんが、納税している法人一覧が載っている分網羅率は高いです。(個人事業主まで対応した商用データベースには負けますが)
また、商用データベースやサービスでは、倒産や合併などのデータが反映されるのは少なくとも登記に反映されてから数か月後の場合が多いですが、国税庁が公開しているこのデータは差分データが毎日リアルタイムで更新されるという強みもあります。
これで十分な場合はそのまま使い、ニーズに合わせてGoogleや他サービスと連携するなり、自分でスクレイピングしてみるのも面白いですね。