cordova-plugin-mobile-ocrを試用してみた結果
ionic公式にも載っているcordova-plugin-mobile-ocrのざっくり検証。

とある画像内の文字列を認識したくて候補の一つとして触ってみましたが、結論から述べるとこのプラグインの実戦投入はやめました。
ただただorzしただけの記事です。
環境
- Android 7.1
- Node.js 10.16.0
- Cordova 9.0.0
- Ionic 5.2.2
インストール
OCR対象画像はカメラ画像にする為、cordova-plugin-cameraも一緒にインストール。
ionic cordova plugin add cordova-plugin-mobile-ocr
ionic cordova plugin add cordova-plugin-cameraインストールされたバージョン。
"cordova-plugin-camera": "^4.1.0",
"cordova-plugin-mobile-ocr": "^3.1.1",実装
OCR結果の文字列は以下のように行単位(lines配列)、語単位(words配列)で返却される。linesの方を画面に表示。

ionic startで作った雛型を編集。
home.page.html。行数分をngForで表示。
<ion-header>
<ion-toolbar>
<ion-title>
Ionic Blank
</ion-title>
</ion-toolbar>
</ion-header>
<ion-content>
<ion-button (click)="executeOcr()" color="primary">OCR</ion-button>
<ion-card>
<ion-card-content *ngFor="let str of ocrStrings">
{{ str }}
</ion-card-content>
</ion-card>
</ion-content>home.page.ts。カメラ撮影→OCRを実装。
import { Component, ApplicationRef } from "@angular/core";
declare var textocr;
declare var navigator;
@Component({
selector: "app-home",
templateUrl: "home.page.html",
styleUrls: ["home.page.scss"]
})
export class HomePage {
// OCR結果の一行を纏めた配列
ocrStrings = [];
constructor(private ref: ApplicationRef) {}
public executeOcr() {
// カメラ起動
navigator.camera.getPicture(
imageData => {
this.ocrStrings = [];
textocr.recText(
0,
imageData,
recognizedText => {
for (
let i = 0;
i < recognizedText.lines.linetext.length;
i++
) {
this.ocrStrings.push(
recognizedText.lines.linetext[i]
);
}
this.ref.tick();
},
err => {
console.error(err);
}
);
},
cameraError => {
console.error(cameraError);
},
{
quality: 100,
correctOrientation: true
}
);
}
}実装完了。
検証
ionic cordova run android、で実機にapkを転送して実行。
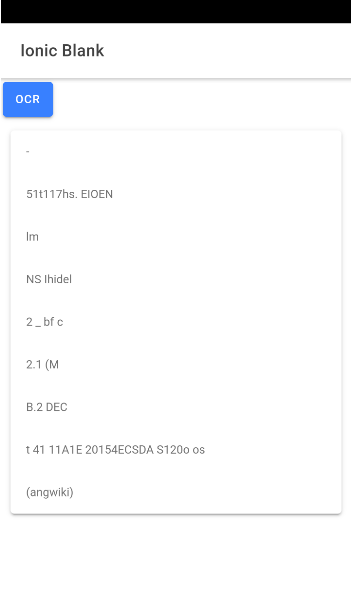
Wikipedia画面をスマホカメラで読み取ってOCR結果を確認してみます。
英語文章を読ませてみる
まぁまぁ読んでくれる。最上位行の次にいきなり途中のContents欄の内容が返ってくるのが謎。


日本語文章を読ませてみる
残念な結果。デバッグコンソールを見ると返却オブジェクトのlanguageがenやらcaなので、日本語としてではなく英語として読もうとしているようです。

CordovaのJSインターフェース定義を見ると、recText関数一つで言語設定引数は無し。
Androidのネイティブ側ソースを見るとGogole Mobile Vision API(
com.google.android.gms.vision.text.*)を使っているようで、iOS側ネイティブコードもGMVDetectorというGoogle Mobile Vision APIを呼び出すクラスを使うようです。
両OSともGoogle Mobile Vision APIを使うのでOCR結果が大幅に異なることは無さそうですが・・・いかんせん読み取り言語の設定APIが見つかりません。
調べてみるとGoogle Mobile Vision APIは「Cloud Vision API」に移行しているそうで、そちらなら言語設定が出来るとのことでした。
https://cloud.google.com/vision/docs/languages
試しては見たものの
Google Mobile Vision APIはもうオワコン(?)
GMV依存であるcordova-plugin-mobile-ocrを使う選択肢は、少なくとも日本人には無さそうです。
Cloud Vision APIを使うか、tesseractの辞書を地道に育てるのが賢明かも知れません。