IVS対応フォント「IPAmj明朝」で使えるフォントをWeb上に一覧表示してみる(2)
前回の続きです。

IPAmj明朝がフォント字体として表示出来るUnicodeとIVSをリストアップしてみたいと思います。
MJ文字情報一覧表をダウンロードする
IPAのサイトから「mji.00601-xlsx.zip」をダウンロードしてきます。
mojikiban.ipa.go.jp
5 Posts
4 Users

MJ文字情報一覧表 | 文字情報基盤整備事業
zipを解凍してxlsxを開いてみます。
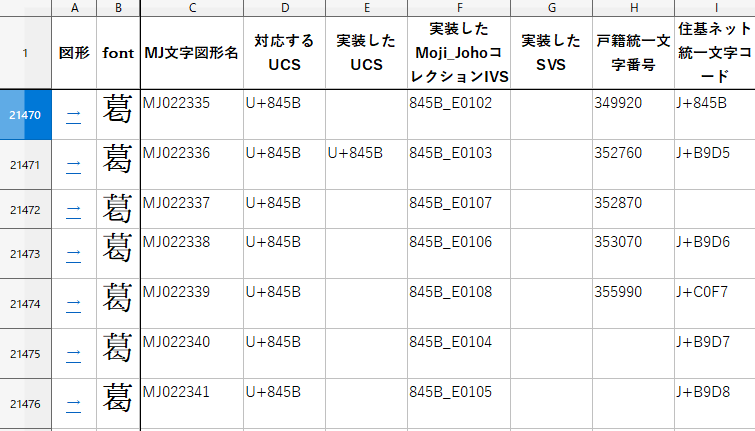
こんな感じで字体、Unicode、IVSの対応が分かります。
(*)fontが化ける場合はIPAmj明朝をダウンロードしてPCにインストールしてください。
Unicodeリストアップ処理を実装する
Apache POIをMaven依存に追加
JavaでExcelシートを読み込む為に「Apache POI」をpom.xmlに加えます。
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>4.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>4.1.0</version>
</dependency>Java実装
読み取ったUnicode、IVSは後からWEBで使えるようにエスケープしています。
package com.example.demo;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.Iterator;
import org.apache.poi.EncryptedDocumentException;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.ss.usermodel.WorkbookFactory;
public class MJUnicodeExtractor {
enum COLUMN {
COL_TARGET_UCS(3), COL_IVS(5);
private int number;
public int getNumber() {
return this.number;
}
private COLUMN(int number) {
this.number = number;
}
}
public MJUnicodeExtractor(String xlsxFileName) throws EncryptedDocumentException, IOException {
Sheet sheet = fetchSheet(xlsxFileName);
createAllFontCsv(sheet);
}
private Sheet fetchSheet(String xlsxFileName) throws EncryptedDocumentException, IOException {
Workbook workbook = WorkbookFactory.create(new File(xlsxFileName));
Sheet sheet = workbook.getSheetAt(0);
return sheet;
}
public void createAllFontCsv(Sheet sheet) throws IOException {
FileWriter fw = new FileWriter("allunicode.lst", false);
PrintWriter pw = new PrintWriter(new BufferedWriter(fw));
Iterator<Row> rows = sheet.rowIterator();
// ヘッダ行読み飛ばし
rows.next();
while (rows.hasNext()) {
Row row = rows.next();
// 「対応するUCS」カラム読み取り
Cell targetUcsCell = row.getCell(COLUMN.COL_TARGET_UCS.getNumber());
String targetUcsCode = getStringCellValue(targetUcsCell);
if(targetUcsCode.length() == 0) {
continue;
}
targetUcsCode = "&#x" + targetUcsCode.split("\\+")[1];
// 「実装したMoji_JohoコレクションIVS」カラム読み取り
Cell ivsCell = row.getCell(COLUMN.COL_IVS.getNumber());
String ivsCellValue = getStringCellValue(ivsCell);
if(ivsCellValue.indexOf(";") > 0) {
ivsCellValue = ivsCellValue.split(";")[0];
}
// IVSを抽出
String ivsCode = "";
if(ivsCellValue.length() != 0) {
ivsCode = "&#x" + ivsCellValue.split("_")[1];
}
System.out.println(targetUcsCode + ivsCode);
pw.print(targetUcsCode + ivsCode);
pw.println();
}
pw.close();
}
private String getStringCellValue(Cell cell) {
String val = "";
if(cell != null) {
val = cell.getStringCellValue();
}
return val;
}
public static void main(String[] args) throws EncryptedDocumentException, IOException {
new MJUnicodeExtractor("mji.00601.xlsx");
}
}実行結果
プロジェクト直下に「allunicode.lst」ファイルが出力されます。エスケープしたUnicodeとIVSを連結して一行ずつ出しています。未実装なものや基となるUnicode文字が無いものは読み飛ばしているので58859行になりました。
(snip)
&#x845B&#xE0102
&#x845B&#xE0103
&#x845B&#xE0107
&#x845B&#xE0106
&#x845B&#xE0108
&#x845B&#xE0104
(snip)「葛(0x845B)」に字体を変化させるIVSが0xE0102・・・と続いているのが分かります。
まとめ
MJ文字情報一覧ExcelファイルからIPAmj明朝で表示出来るフォントのUnicodeリストが出来ました。
次回はこのリストを元にWeb上でフォント表示してみます。